深度学习后训练的范式革新:冷启动阶段隐藏的「多样性陷阱」与自适应早停机制
2025年,强化学习(RL)成为大语言模型后训练的主流范式。不依赖海量人工标注,仅靠RL就能激发复杂推理和长思维链能力,甚至达成超人类表现。这是行业的共识,也是技术演进的方向。
但现实很骨感。
把普通基座模型直接扔给RL算法,在有限步数内根本无法探索出正确推理路径。缺乏方向性引导的RL,就像无头苍蝇四处乱撞。这是每一个深度学习工程师都踩过的坑。
实战中的关键节点:从SFT冷启动到RL训练的过渡困境
目前的标准解法是:在RL之前,先用少量优质数据进行监督微调(SFT),给模型做「冷启动」热身。看似合理的流程设计,实则暗藏玄机。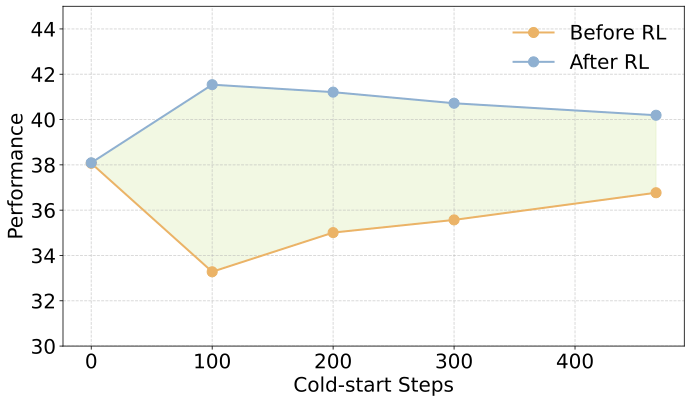
核心问题来了:SFT到底要训练到什么程度?
传统经验告诉我们,SFT的损失越低、准确率越高,说明模型学得越好。按照这个逻辑,测试集准确率最高的checkpoint,应该是RL效果最好的起点。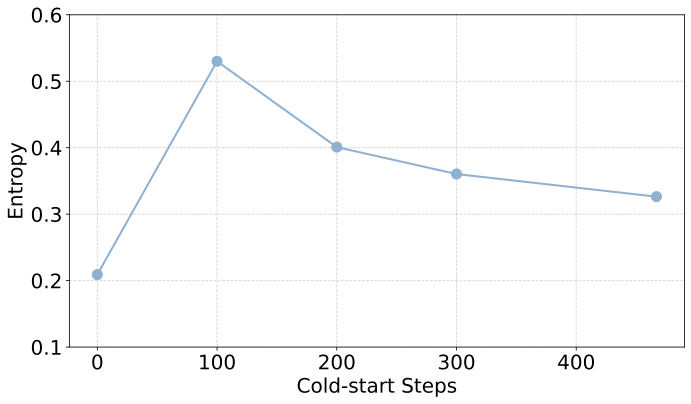
但港科大、阿里、厦大的联合研究团队,用实验数据狠狠打了这个结论的脸。
他们发现:冷启动阶段评估性能最好的checkpoint,拿去跑RL后,最终成绩往往不是最好的,甚至会倒退。这种「南辕北辙」的现象,困扰了无数研究者和开发者。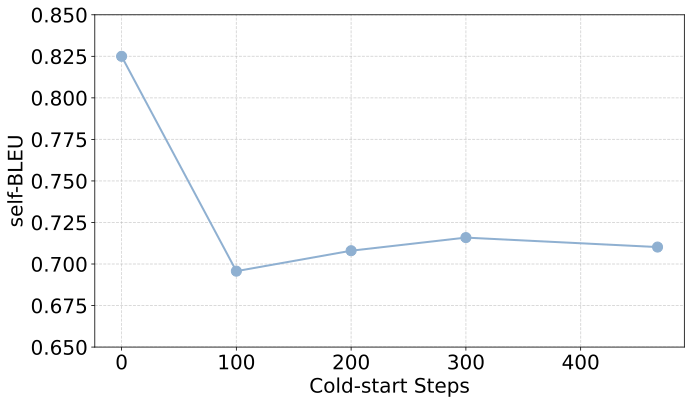
技术复盘:为什么「好学生」反而跑不远
问题的根源在于「作为RL冷启动的SFT」与「单纯的SFT」在核心目标上存在根本分歧。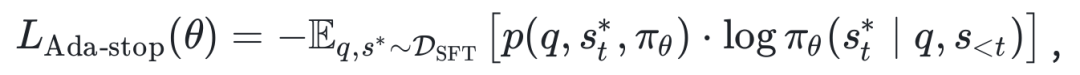
传统SFT范式中,数据集充足且丰富,交叉熵损失完美契合「尽可能多地从数据中学习」的目标。但在RL冷启动阶段,情况完全不同。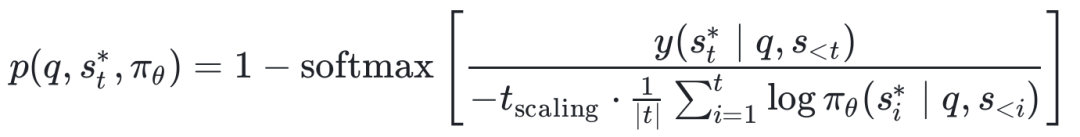
数据量有限。过度优化会导致模型过拟合,变成单纯「背诵」小数据集。RL算法的成功高度依赖「探索(Exploration)」与「利用(Exploitation)」的平衡。如果模型在进入RL阶段前就丢失了输出多样性,RL阶段就会因为探索空间不足,导致最终效果大打折扣。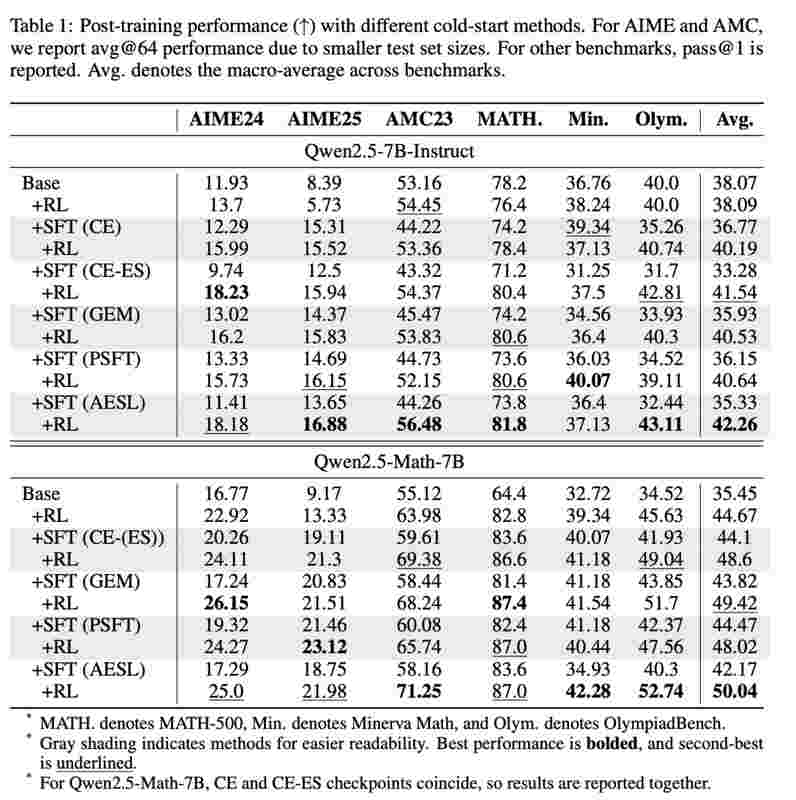
基座模型就像充满想象力但缺乏解题套路的孩子。SFT冷启动的目的,是教它基本的解题格式。但如果训练过度,传统交叉熵损失会强迫模型死记硬背演示数据的每一个细节。模型虽然学会了套路,却丢失了原本丰富的知识分布和生成多样性。当这个「做题机器」进入RL阶段时,它已失去探索新路径的能力,RL的上限被死死锁住。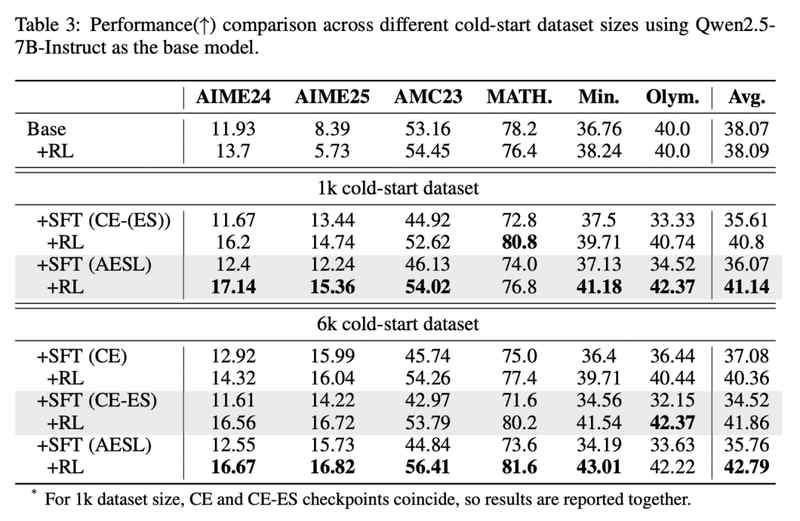
方法提炼:AESL损失函数的创新设计
研究团队追踪了模型在冷启动训练过程中的熵(Entropy)和self-BLEU分数。奇妙的现象出现了:SFT早期,模型在学习新推理格式的同时,还保留着基座的原始知识,多样性达到峰值。随着训练继续,模型开始过拟合,多样性迅速暴跌。这个多样性的「黄金拐点」,恰恰对应着RL潜力的最高点。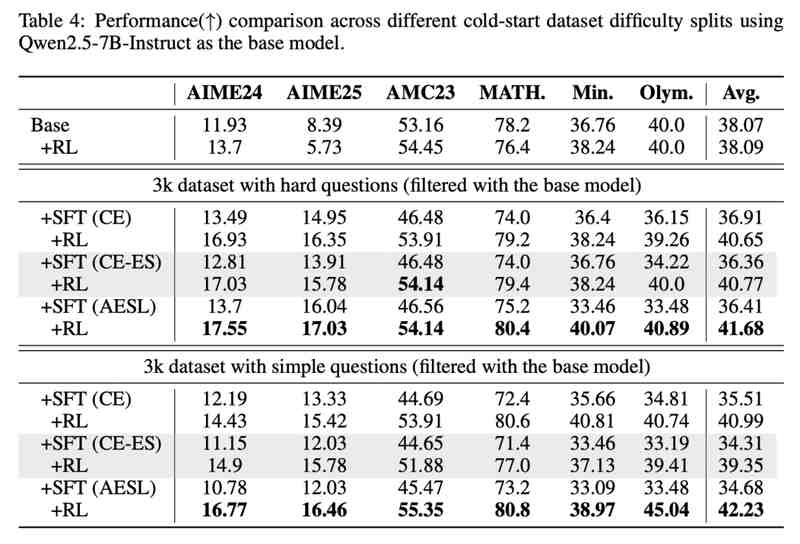
最简单的改进方法是「基于多样性早停」。但「一刀切」的全局早停忽略了一个事实:模型对不同Token和不同上下文的掌握速度完全不同。
基于此,团队提出自适应早停损失(AdaptiveEarly-StopLoss,AESL)。核心哲学是「因材施教」,在Token和Subsequence两个微观层面上动态调节学习力度。
Token级别调控:生成每个词时,如果模型当前预测概率已经很高,AESL会自动降低该Token的损失权重。就像告诉模型:「这道题你已经会了,不用反复抄写,保留你原本的直觉。」这有效防止了对特定词汇的过拟合。
Subsequence级别调控:AESL会实时计算当前生成前缀的平均置信度。如果前半句话已经非常符合目标分布,AESL会在后续生成中放宽限制。就像走迷宫:前面走对了方向,后面就可以大胆探索;前面不确定,后面就老实跟着指示走。
实践验证:数学推理任务上的性能对比
研究团队在AIME24/25、AMC23、MATH-500等榜单上进行了大规模实验。选用Qwen2.5-7B-Instruct、Qwen2.5-Math-7B及Llama-3.1-8B-Instruct作为基座进行测试。
结果显示:无论在哪种基座模型上,使用AESL作为冷启动策略,其后续经过RL训练的最终性能,全面碾压直接RL、标准CE损失SFT及其他前沿方法。
更关键的是,无论数据多寡、无论数据难易,AESL都能稳定发挥,始终提供优于传统方法的RL潜力。
应用指导:从理论到落地的关键路径
AESL的提出,不仅仅是一个损失函数的改进,更是对LLM后训练范式的认知刷新。它打破了「SFT拟合越好越好」的迷思,证明了在冷启动阶段,「保持多样性」比「满分模仿」在后续RL训练中更具长期价值。
代码已全面开源(github.com/LXXXXR/AESL),可供直接调用。对于正在构建RL训练流程的团队,建议立即将SFT阶段的目标从「准确率最大化」调整为「准确率与多样性的动态平衡」,AESL提供了现成的技术方案。
多样性的丢失,可能早于RL阶段的开始。这项研究为所有深度学习工程师敲响了警钟:在后训练的每一个环节,都需要对多样性保持敬畏。
